

{kind=link}
{kind=link}
{kind=link}
{kind=link}
多点统计地质建模技术研究进展与应用*
[王鸣川 , 段太忠, 计秉玉]
, 段太忠, 计秉玉]
, 段太忠, 计秉玉]
|
|

第一作者简介 王鸣川,男,1985年生,博士,中国石化石油勘探开发研究院工程师,主要从事储集层建模与油藏数值模拟研究。E-mail: wangmc.syky@sinopec.com。
通讯作者简介 段太忠,男,1961年生,博士,中国石化石油勘探开发研究院国家“千人计划”特聘专家,主要从事储集层表征与建模研究。E-mail: duantz.syky@sinopec.com。
多点统计地质建模技术自提出至今已有 20余年的历史,已经成为储集层地质建模的国际前沿研究方向,在理论和应用研究方面都取得了长足进展。以多点统计地质建模技术的发展历程为主线,以多点统计地质建模技术的技术进展为核心,论述了多点统计地质建模技术的研究进展,对主要的多点统计地质建模方法进行了分类,系统讨论了具有发展潜力的多点统计地质建模方法的原理、特点以及存在的问题,并以扎格罗斯盆地孔隙型碳酸盐岩油藏 S油藏为例进行了应用研究,对比了多点统计模拟与序贯指示模拟的优劣。研究表明,多点统计模拟在复杂的相模拟方面,较序贯指示模拟具有明显的优势;基于图型的 Dispat方法采用图型替换数据事件的策略,使相的分布规律更符合地质学家的地质认识。这一认识为孔隙型碳酸盐岩油藏建模提供了一种新思路,对类似油藏的地质建模具有借鉴作用。
About the first author Wang Mingchuan,born in 1985,is a doctor and reservoir engineer at Petroleum Exploration & Production Institute,SINOPEC. His research interest is reservoir geological modeling and numerical simulation. E-mail: wangmc.syky@sinopec.com.
About the corresponding author Duan Taizhong,born in 1961,is a doctor and distinguished expert of national “The Recruitment of Global Experts” at Petroleum Exploration & Production Institute,SINOPEC. His research interest is reservoir characterization and modeling. E-mail: duantz.syky@sinopec.com.
Multipoint statistics(MPS)geological modeling technology has been put forward for more than 20 years,and it has become the international frontier research direction of reservoir geological modeling. Great progress has been made in both theory and application of MPS geological modeling technology. Taking the development history of MPS as the main clue,and the technical progress of MPS as the core,the paper discussed the research progress of MPS,classified the main MPS methods and systematically discussed the principle,characteristics and existing problems of potential MPS geological modeling methods. Finally,MPS geological models of porous carbonate Reservoir S in Zagros Basin were set up,and pros and cons of the MPS and sequential indicator simulation(SIS)were compared. Research shows that MPS has obvious advantages in complex facies modeling compared with SIS,and Dispat,a pattern-based modeling method,makes the facies distribution more accordant with the geological understanding of geologists by utilizing the strategy of replacing data event with pattern. The research results provide a new geological modeling method for porous carbonate reservoirs,and could be a reference for geological modeling of similar reservoirs.
1960年代以来, 地质统计学建模方法获得了巨大的发展, 已经成为目前地质建模的主要方法, 主流地质建模软件都将地质统计学作为其算法核心。传统的地质统计学建模方法主要为两点统计学方法, 如序贯高斯模拟、序贯指示模拟等。这类方法以变差函数为工具, 只能同时考虑本征假设下两点之间的相关性, 难以表征储集层及地质体的空间结构和几何形态(图 1)。在砂体平面展布差异巨大的情况下(图 1-a至1-c), 两点统计得到的东西向(图 1-d)和南北向(图 1-e)变差函数基本相同。虽然以序贯指示模拟为代表的两点统计相建模方法应用广泛, 但是对其无法再现地质体形态的质疑一直存在。并且, 为了克服两点统计建模方法的缺点, 地质建模研究和应用人员采用多种方法对建模效果进行改善(Xu et al., 1993; Xu, 1996)。但是, 两点统计建模方法固有的不足难以从根本上克服。
 | 图1 难以精确反映储集层各向异性的变差函数(据Caers and Zhang, 2002)Fig.1 Variogram of inaccurate reflection of reservoir anisotropy(after Caers and Zhang, 2002) |
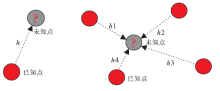
鉴于传统两点统计地质建模方法在储集层信息分析方面只能考虑空间上两点之间相关性的不足, 采用多点的联合分布对储集层内部结构和形态进行建模的方法应运而生(图 2)。多点统计地质建模方法应用“ 训练图像” 代替两点统计建模方法里的变差函数, 来表征地质变量的空间结构和变化, 可以克服传统两点统计地质建模方法不能较好再现地质体空间几何形态的不足; 同时, 多点统计地质建模方法采用基于象元的序贯模拟过程, 而非基于目标的随机模拟方法的迭代试错的模拟过程, 容易条件化井数据和其他地质信息, 提高计算效率, 加之“ 训练图像” 的使用, 无须提供目标体的几何形态参数, 克服了基于目标的随机模拟方法的不足(吴胜和和李文克, 2005; Hu and Chugunova, 2008)。综合了已有建模算法优点的多点统计地质建模方法, 是目前地质统计学建模技术的一个重要发展方向。
 | 图2 两点与多点地质统计学方法示意图h为两点统计建模方法中已知点与未知点之间的距离, h1~h4为多点统计建模方法中各已知点与未知点的距离Fig.2 Geostatistical method sketch of bi-point and multipoint |
多点统计地质建模方法于1992年首次提出(Journel, 1993), 并开始在随机建模中实现应用(Guardiano and Srivastava, 1993)。但真正的实际应用则直到2000年Snesim建模方法提出后才成为可能(Strebelle, 2000; Strebelle and Journel, 2001)。多点统计地质建模方法主要包括2大类, 即迭代和非迭代方法。迭代法主要有Deutsch(1993)提出的模拟退火方法、Srivastava(1992)提出的基于吉布斯取样的后处理迭代法、Wang(1996)提出的生长算法和Caers和Journel(1998)提出的基于神经网络的马尔科夫蒙特卡洛法。由于迭代法收敛条件苛刻、计算速度慢, 使得迭代法在实际油气藏建模应用中受到很大限制, 一直停留在实验阶段, 难以投入实际应用。Guardiano 和 Srivastava(1993)提出一种非迭代的建模算法(简称为直接法), 并首次尝试将多点地质统计学应用于实际地质建模工作中。直接法应用数据模板扫描训练图像, 利用生成的多个随机变量推断出未知点的条件概率。相对于迭代法, 直接法较为简单, 不受收敛问题的限制, 但每模拟一个网格点都需要重新扫描训练图像, 导致数据量庞大、计算量大、计算速度低下, 很难真正应用于实际地质建模工作中, 但是, 非迭代算法的提出为多点统计地质建模算法的研究注入了新思维。Strebelle和Journel(2001)在直接法的基础上, 应用“ 搜索树” 这一数据存储结构, 提出了Snesim建模方法, 不需要每次模拟都重复扫描训练图像, 有效提高了计算效率, 推动了多点统计地质建模的发展, 为多点统计地质建模方法应用于储集层建模奠定了基础。Apart等(Apart and Caers, 2004, 2007; Arpat, 2005)提出了基于图型的Simpat建模方法, 通过对训练图型和数据事件进行对比, 寻找相似度最高的训练图型置入模拟网格, 1次模拟1个数据模版内的所有节点, 同时采用双模板模拟的办法, 一定程度上改进了Snesim建模方法导致的目标体不连续问题。Zhang等(2006)针对Simpat建模方法数据事件匹配训练图型时搜索计算量大、计算较慢的不足, 提出了Filtersim建模方法, 通过线性过滤器将训练图型进行聚类, 识别不同类型数据图型所代表的地质特征, 然后进行数据事件与训练图型类的相似性判断, 从最相似的训练图型类里随机挑选训练图型替换当前数据模板处的数据事件, 降低了多点统计地质建模计算过程中的数据维度, 提高了计算效率, 但增加了图型选取的随机性。Eskandari和Srinivasan(2007, 2010)改进了早期的生长算法和Snesim算法, 提出了更加适用的Growthsim算法, 通过已知点(或已模拟点), 采用贝叶斯定理1次模拟1个图型, 提高了算法的计算效率。Honarkhah和Caers(2010, 2012)为了提高训练图像图型再现的准确性, 通过MDS(多维尺度法)和Φ 变换, 采用kernel空间映射, 得到1种改进的图型分类方法, 并基于此提出了Dispat多点建模算法, 对Filtersim建模算法进行了改进。Mariethoz等(2010)、Abdollahifard和Faez(2014)鉴于传统多点模拟技术不能全面挖掘训练图像内部信息、辅助数据处理技术要求高的缺点, 提出了无需数据预处理和多尺度网格的DS多点建模算法, 一定程度上降低了多点统计建模算法对训练图像的平稳性要求, 提高了多点统计地质建模算法的灵活性。随着对多点统计建模方法研究的深入和计算机性能的提高, 不同研究兴趣的研究人员对目前的多点统计建模方法进行了卓有成效的改进和提高。Wu等(2008)对Filtersim建模算法中的过滤器进行了改进, 提出了基于分数距离的图型和数据事件聚类方法, 在3D建模的应用中, 其模拟速度较Filtersim建模算法提高了10倍。Mohammadmoradi和Rasaei(2012)通过对图型的提取、迁延和置入步骤进行修改, 提高了Filtersim建模算法的建模效果。Honarkhah和Caers(2012)在Dispat建模算法基础上, 通过将空间坐标加入到图型的相似度计算中, 降低了非平稳地质现象模拟对趋势和辅助变量的要求。Abdollahifard和Faez(2014)采用快速梯度下降图型拟合策略进行快速采样, 提高了DS建模算法的计算效率。同时, 研究人员(Ortiz and Deutsch, 2004; Ortiz and Emery, 2004; Abdollahifard and Faez, 2013; Sebacher et al., 2015; Gardet et al., 2016)将多点统计地质建模方法与其他建模方法结合, 进行了多种建模方法耦合的尝试和研究。Huang等(2013)利用GPU的高性能提高多点统计地质建模算法的计算效率, Straubhaar等(2013)采用并行算法提高多点统计地质建模算法的计算效率。另外, 在多点统计地质建模的训练图像获取与建立(Pyrcz et al., 2008; Pickel et al., 2015)、计算参数优选(Mariethoz and Renard, 2010; Meerschman et al., 2013; Zhang et al., 2015)方面, 都有大量的探索和研究。总体来看, 国外在多点统计地质建模技术领域一直领先于国内, 对理论的进展和实际应用做出了里程碑式的贡献。国外多点统计地质建模研究主要以碎屑岩, 尤其是河流相砂岩和浊积岩的地质建模研究为主, 对碳酸盐岩储集层包括孔隙型碳酸盐岩储集层多点统计地质建模方面, 目前还处于理论探索阶段, 多以合成模型的实验研究为主, 应用研究相对较少。
吴胜和和李文克(2005)在渤海湾盆地某区块相建模中对比了Snesim多点地质统计学建模方法与序贯指示模拟方法的建模效果, 发现多点地质统计学随机建模比传统两点统计学建模方法具有明显的优越性。冯国庆等(2005)、张伟等(2008)基于多点地质统计学原理, 利用Snesim建模方法建立了研究区的岩相和沉积微相模型, 取得了较好的效果。骆杨和赵彦超(2008)则应用多点地质统计学原理对河流相储集层主要是辫状河分流河道进行了模拟, 并对目标体的连续性等多点地质统计学面临的主要问题进行了讨论。李少华等(2009)用2种方法对河道砂体的属性分布做了模拟:一种是局部变化均值方法, 另一种是多点地质统计学方法; 通过对比分析, 他认为2种方法各有优缺点且都需进一步完善。尹艳树等(2008a)通过基于目标体的方法生成线模型, 在Simpat建模方法的基础上加入了线约束, 很好地解决了多点地质统计学模拟河道易断裂的问题。尹艳树等(2008b)提出了基于储集层骨架的多点统计地质建模方法(SMPS), 对 SMPS 方法的原理及建模流程进行了详细阐述, 并与序贯指示、Snesim、Simpat方法进行了对比, SMPS 方法能够更准确地建立二维河流相沉积模型。尹艳树等(2014)提出基于沉积模式的多点统计地质建模方法, 通过距离函数将储集层特征与沉积位置相关联, 采用整体替换、结构化随机路径以及多尺度网格策略再现沉积模式, 解决了非平稳储集层建模过程中的非平稳性模拟问题, 在鄱阳湖三角洲前缘沉积地层的应用证实了该方法的适用性。石书缘等(2011)提出基于随机游走过程的多点统计地质建模方法(RMPS), 通过7个方向迁移概率计算及4个方向河道源头搜索的随机游走过程的改进, 实现了高曲率回旋河道和网状河等模拟以及各种类型河流相的主流线预测, 应用表明RMPS比传统多点统计地质建模方法能更好地再现河道的形态, 并具有一定的稳定性。冯文杰等(2014)在Snesim建模方法的基础上, 提出基于地质矢量信息的多点统计地质建模算法(VMPS), 通过概念模型和实际储集层模拟, 验证了VMPS的模拟效果优于Snesim, 能适应“ 非平稳性” 突出条件下的地质建模。在理论方法探索的基础上, 很多研究人员也通过不同储集层类型对多点统计地质建模方法进行了应用研究(杨宏伟, 2010; 周金应等, 2010; 刘学利和汪彦, 2012; 陈培元等, 2014; 付斌等, 2014; 李康等, 2014; 王东辉等, 2014; 陈更新等, 2015; 张文彪等, 2015), 均取得了一定效果, 一定程度上满足了油田生产中对储集层建模的需求。国内多点统计地质建模技术的研究以应用研究和对国外理论算法的补充研究为主, 原创性的理论算法研究较少。国内针对碳酸盐岩油藏的多点统计地质建模研究应用于缝洞型碳酸盐岩储集层, 主要用于描述孔洞的分布。
多点统计学地质建模算法总体上可以分为迭代和非迭代2大类(表 1)。迭代类算法由于收敛困难, 难以应用于实际油藏的地质建模, 目前已经少有研究。相较于迭代类算法, 非迭代类算法采用直接或间接从训练图像中获取条件概率或相似度, 提高了算法效率, 并通过不断改进和完善, 逐渐应用于实际油藏地质建模中。其中, Snesim、Simpat和Filtersim这3种算法是目前研究最多的多点统计地质建模算法, 其理论、特点及存在问题在文献中多有论述(Strebelle and Journel, 2001; Arpat, 2005; Zhang et al., 2006; 尹艳树等, 2011), 此处重点探讨新近出现的Growthsim、Dispat和DS这3种算法。
| 表1 多点统计地质建模算法分类 Table1 Classification of MPS geological modeling algorithm |
Growthsim建模算法综合了生长算法和Snesim算法的特点, 通过数据事件中的已知点(或已模拟点), 利用最优空间数据模板, 逐渐“ 生长” 出图型, 最后生长出整个模型(Eskandaridalvand and Srinivasan, 2010)。与基于迭代框架下的生长算法不同(Wang, 1996), Growthsim算法采用序贯路径, 根据相应图型的概率生长出数据模板处可接受的数据事件。相应图型的概率是通过单一贝叶斯定理来计算的:
式中, A为模拟图型, B为条件图型, P(A, B)为从多点直方图中得到的模拟和条件图型的联合概率,
与Snesim算法1次只模拟数据事件的1个中心点不同, Growthsim算法1次完成1个图型的模拟, 同时, Growthsim算法允许基于相邻多点图型所作的推断和模拟, 这一改变使其成为一种基于“ 生长” 的高效的建模方法。
Growthsim算法的“ 生长” 特性使其可以方便快速地模拟地质空间内复杂的结构特征, 但是由于其根本上基于图型概率对模拟网格进行图型置入, 使得其随机性较强, 而且难以模拟非平稳地质现象。
Dispat建模算法针对以前基于图型建模算法在图型聚类和模拟方面的不足, 放弃简单的采用过滤器逐点对比图型与数据事件的相似性的办法, 对扫描自训练图像的图型进行多维尺度变换(MDS), 在保留图型原始结构和数值的前提下将图型转换成欧氏空间里的点, 因此, 可采用距离函数直接对比训练图像中所有图型之间的差异; 再在kernel特征空间对“ 点” 进行Φ 变换, 即可得到“ 图型点” 的线性展布; 接着采用kernel函数对图型进行聚类。Kernel函数如下(Honarkhah and Caers, 2010):
式中,
Dispat建模算法通过空间转换实现相似度对比函数(距离函数)的降维, 在此基础上的图型聚类比Filtersim算法的聚类更加准确, 一定程度上降低了图型选择的随机性, 而且由于降维, 同等条件下计算效率比Filtersim算法大幅提高。但是, 由于Dispat算法是Filtersim算法在图型聚类方法上的改进, 所以与Filtersim算法一样, Dispat算法也无法很好地模拟非平稳地质现象。
针对以往概率型或相似度型建模算法的不足, Mariethoz等(2010)提出DS建模算法。该建模算法首先确定数据事件的尺寸, 并按照数据事件的尺寸确定搜索窗口; 接着采用序贯模拟方式, 随机扫描搜索窗口; 根据图型与数据事件的的相似度确定符合条件的图型; 最后将已选择的图型的中心点的值, 赋给模拟网格中数据事件的中心点。图型与数据事件的相似度采用如下函数表示:

其中:
式中,
DS建模算法直接从训练图像中采样, 所以不需要数据库存储, 可以降低算法对内存的要求; 另外, 随着模拟的逐点进行, 已知点(包括已模拟点)密度增大, 数据模板尺寸自动变小, 便于刻画各个尺度的地质现象, 从而无需多尺度网格参数。DS建模算法是近年出现的一种较为理想和实用的基于图型的建模算法, 具有快速、易于并行、内存需求低和直接的特点。但是, 模拟路径的随机性会导致建模算法盲目搜索, 从而增加了计算量。目前这一算法正在不断改进中(Abdollahifard and Faez, 2014)。
鉴于目前多点统计地质建模技术多应用于河流相和浊积岩相油藏, 国内虽对缝洞型碳酸盐岩油藏多点统计地质建模有所探索, 但是, 对于建模困难的孔隙型碳酸盐岩油藏目前尚无研究报道。目前多采用岩石类型(rock type)对孔隙型碳酸盐岩油藏复杂的属性规律进行约束, 但是, 传统的两点地质统计学建模方法无法有效刻画岩石类型复杂的空间变化规律和展布形态, 难以建立复杂的岩石类型三维模型。下面基于较为成熟的Snesim多点统计建模算法, 以扎格罗斯盆地孔隙型碳酸盐岩油藏S油藏为例, 进行岩石类型多点统计地质建模研究。同时, 为了对比不同多点建模方法的优劣, 采用目前较为先进的Dispat多点统计地质建模方法, 建立了S油藏岩石类型模型。
S油藏平均埋藏深度3000, m, 为白垩系孔隙型碳酸盐岩油藏, 面积500, km2, 平均地层厚度500, m, 井数33口, 平均井距2000, m, 目前处于一期开发阶段, 油藏复杂, 稳产上产难度大, 基于两点统计学的油藏模型对开发方案的预测性差。因此, 采用目前应用最为广泛的Snesim多点统计建模方法以及新近出现的Dispat多点统计地质建模方法, 建立S油藏的岩石类型模型。
考虑研究区地质模型拟划分的网格节点数, 将训练图像的网格数设置为120× 120× 36, 共518, 400个网格。综合S油藏的地质模式、测井、地震数据, 在地震三维体数据的基础上, 采用人机互动方法, 建立研究区的三维训练图像(图 3)。
 | 图3 S油藏训练图像Fig.3 Training image of Reservoir S |
Snesim建模的基本步骤为: (1)建立训练图像; (2)设置数据模板大小和多尺度网格级数, 优选数据搜索参数, 建立概率分布搜索树; (3)沿着搜索路径对待模拟网格节点进行序贯模拟, 建立岩石类型三维模型。
根据训练图像网格数和多尺度网格的级数, 将数据模板的大小设置为9× 9× 3, 搜索网格级数为3级, 使得在最粗级别网格上, 横向搜索网格为72个, 纵向搜索网格为24个, 不超过训练图像尺寸的2/3, 又能最大限度获取训练图像的信息。在此基础上, 建立训练图像在数据模板扫描下各个数据事件的概率分布搜索树, 用以储存搜索概率。
在搜索树建立后, 应用Snesim算法, 对研究区岩石类型进行建模。数据准备、随机路径选取和序贯方法设置的具体步骤与传统的两点统计学建模方法类似, 岩石类型采用Snesim多点统计建模方法。在研究区岩石类型多点统计地质建模过程中, 需要综合地震数据对岩石类型的展布进行约束, 因此, 需要对
其中,
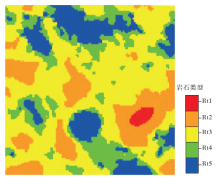
研究区Snesim模型如图4-c所示。从图中可以看出, Snesim模型在忠实于井信息的基础上, 既能很好地反映训练图像所综合的地质结构信息, 又能很好地反映岩石类型在区域的变化特征和规律。岩石类型在平面上由好逐渐变差, 与碳酸盐岩缓坡礁滩和滩间的沉积环境、物性具有较好的对应关系。传统两点统计学(基于变差的序贯指示模拟方法)建模方法所建立的模型(图 4-a), 由于只能把握两点间的相关性, 导致岩石类型主要集中在具有分布优势的Rt2和Rt4上, 平面上岩石类型之间的变化呈现出快速突变的特征, 不太符合地质认识。在传统两点统计建模基础上, 增加地震数据进行协同模拟(图 4-b), 虽然在一定程度上改善了不同岩石类型之间的接触, 使模拟的岩石类型种类更加丰富, 但不同岩石类型间的接触较为杂乱, 不符合地质学家对相分布的认识。
 | 图4 S油藏地震波阻抗及地质模型a— 序贯指示模拟模型; b— 地震协同序贯指示模拟模型; c— Snesim模型; d— Dispat模型; e— 地震波阻抗Fig.4 Seismic acoustic impedance and geological models of Reservoir S |
为了对比不同多点统计地质建模方法的建模效果, 采用目前较新出现的Dispat建模方法建立S油藏同层位的岩石类型模型。Dispat方法建模的基本步骤为: (1)建立训练图像; (2)设置数据模板大小、多尺度网格级数、MDS维度等参数, 建立训练图型库; (3)设置替换模板大小, 沿着搜索路径对待模拟网格节点进行序贯模拟, 建立岩石类型三维模型。
为便于Dispat模型与Snesim模型的对比, 在采用Dispat建模方法建模时, 数据模板的大小和多尺度网格的级数与Snesim建模方法所选用的参数一致, Dispat建模方法所需的其他参数, 如替换模板的大小、MDS空间维度等, 选用Dispat建模方法的最优参数, 所建模型如图4-d所示。由于Dispat建模方法采取了训练图型替换数据事件的随机模拟策略, 而非Snesim建模方法的点模拟方式, 模拟结果(图 4-d)不仅具有Snesim建模方法的优点, 能够较好地模拟岩石类型的种类与接触关系, 较好地反映沉积环境和物性的对应关系, 而且各岩石类型的连续性更好, 能够更好地反映训练图像和井震数据所包含的地质信息, 使模型更符合地质学家的地质认识。从不同建模方法所建立的模型可以看出, 多点统计地质建模对于复杂孔隙型碳酸盐岩油气藏具有明显的优越性, 能够更好地再现岩石类型的复杂展布特征和规律, 为属性模拟提供高质量的约束模型。同时, Dispat建模方法由于采用训练图型替换数据事件, 而非Snesim建模方法的中心点替换, 相的连续性更好, 模拟结果更符合地质学家的地质认识。
多点统计地质建模方法自提出至今已20余年, 国内外学者在多点统计地质建模理论和应用方面进行了大量研究并取得显著进展。多点统计地质建模算法从迭代类算法演进为非迭代算法, 并出现概率型和相似度型2种非迭代多点统计地质建模算法, 使多点成为一种可实用的随机建模方法, 并且建模效果不断改善。
扎格罗斯盆地孔隙型碳酸盐岩油藏岩石类型的模拟结果显示, 多点统计地质建模方法在无明显分布规律的相的模拟方面, 较传统的两点统计地质建模方法具有明显的优势; 基于图型的Dispat方法由于采用图型替换数据事件的模拟策略, 使岩石类型的连续性较Snesim建模方法更好, 更真实地反映岩石类型在区域的变化特征和规律, 更加符合地质学家的地质认识。
多点统计地质建模技术综合了基于象元建模方法容易整合条件数据, 以及基于目标的建模方法容易刻画地质体形态的优点, 是目前地质统计学建模技术的一个重要发展方向。但在训练图像获取、非平稳地质现象模拟和考虑地质含义的建模算法方面, 仍不完善, 需要深入研究。
多点统计地质建模技术在国外发展迅速, 推出了较多的原创性算法, 国内更注重多点统计地质建模技术的应用。多点统计地质建模作为一种新的建模方法和技术, 如何运用其特点解决复杂油气藏, 尤其是碳酸盐岩油气藏的建模问题, 是当前需要重点攻克的方向。中国应该加强原创性算法研究以及算法的软件化和商业化, 使中国在储集层表征与建模技术领域具有更大的国际竞争力。
作者声明没有竞争性利益冲突.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|
| [53] |
|
| [54] |
|
| [55] |
|
| [56] |
|